Speeding up Product Development with Redux Modules
When we began phasing out Angular in favor of React, we took Redux into use to manage the global application state. In this blog post, I'll explain how we use Redux modules at Smartly.io to create a maintainable codebase.
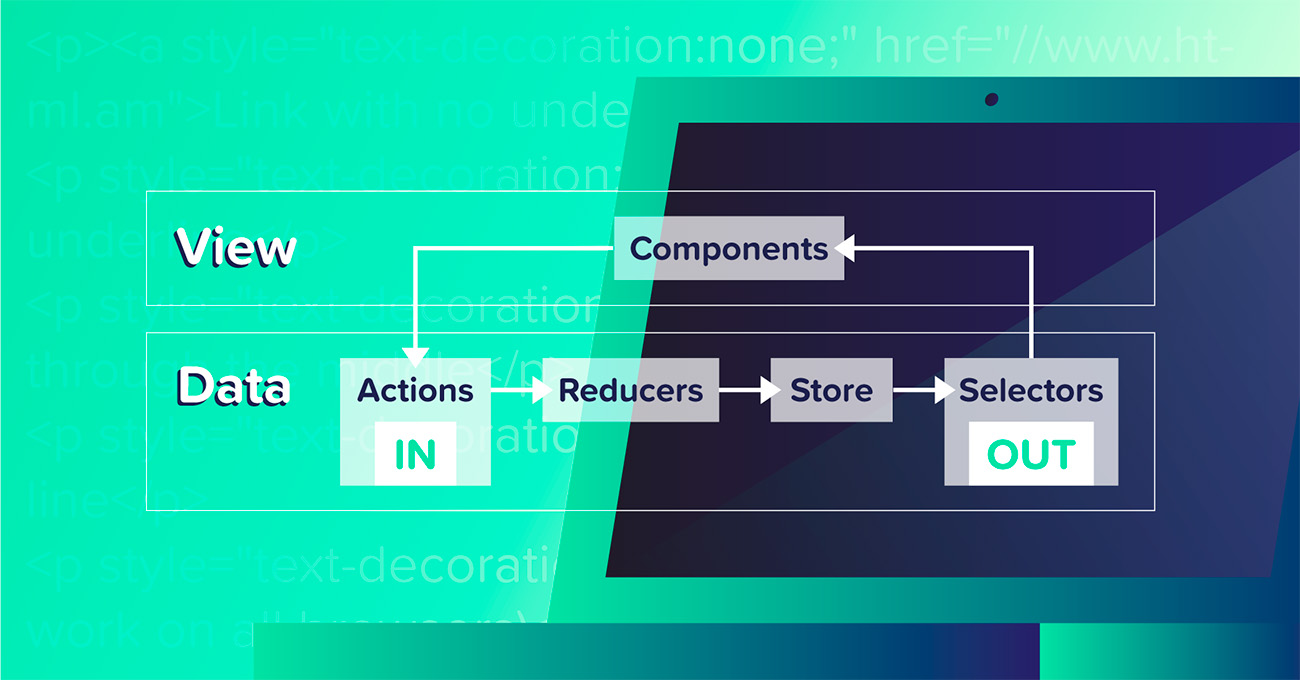
As a Flux-like implementation, Redux follows a unidirectional data flow architecture, which, in Redux’s terms, means that whenever you need to make a change to an application’s state, you dispatch an action to the store. Reducers in the store then decide if they need to make any changes to their own state, depending on the action. Finally, the new state propagates to the view layer to all the components that are listening to the changes.
This pattern takes all the hassle away from debugging your application state, as only the reducers change your application state and they work exclusively based on the dispatched actions. However, there is more to be done for a clean Redux codebase and that’s where the modules come in!
In and out
When developing React components, it is a commonly encouraged pattern to split the logic and view. With our Redux setup, we aim to split the state logic and view layer completely. Providing clear APIs for interacting with the application state allows us to isolate the inner workings of our state machine from the view layer. In Redux, those APIs are actions for changing state and selectors for reading the state. Let’s talk more about actions and selectors later.
Redux as modules
The module structure for Redux is all about dividing code by domain areas and eliminating dependencies between the modules. When a developer needs to make changes to the massive code-base it is easier to find out which module is responsible for the area requiring the changes, how different actions affect the module state, and what you can actually pull out from the module. One example of a module could be named “Campaigns” with the responsibility of managing lists and details of user’s campaigns within the application state tree.
What do the modules contain?
The “Campaigns” module provides its own reducer, actions, selectors, and optionally some utils, constants etc. The utils in this case are any functional helpers that are related to the domain of the module.
Typical module structure is as follows:

1. Reducer
The module reducer will manage a very specific subset of the whole application state. A “Campaigns” module reducer would only be managing state related to campaigns: list of campaigns, changes to campaign data, loading states for the module data etc. The whole application state is managed by a combined reducer built with all of our individual module reducers.
The application state with the different modules mounted on it might look something like this. The individual keys represent the modules and their own areas of responsibility.
2. Action creators
The module also contains action creators for creating actions that will be handled by its reducer. We decided to name our actions with the pattern <project>/<module>/<ACTION_NAME> so ie. “smartly/campaigns/CREATE_CAMPAIGN”. The pattern is known from Erik Rasmussen’s proposal “Ducks: Redux Reducer Bundles”. The pattern makes it easy to spot the right project, right module, and right action when looking through the list of actions in Redux DevTools. This naming convention also helps avoid clashes in naming. Clashes can cause weird states as Redux doesn’t care where the action came from—it only cares about the “action.type” string when matched with reducer’s action handlers.
3. Selectors
Redux already takes good care of making sure all state changes are caused by dispatching actions to the store. However, when connecting your components to the store, the whole state is usually passed to the component. In some cases, it might be tempting to simply pick data like “state.myLittleModule.items”,ut then you’re actually making your data component aware of the shape of your whole state. What happens when “items” is no longer under “state.myLittleModule”?
The module specific selectors are used to pull data from the part of the application state that represents the module. Each module provides its own selectors for directly reading the module state. We typically use selectors in a Higher-Order Component that maps the selected values as props for our component. The selectors are called with the application state and, optionally, some additional arguments.
The additional arguments can be used ie. in a selector “getCampaignsByAccountId” to provide the selector with the account ID for filtering. Developers should make sure that the module selectors only read those parts of the data that are covered by the module itself. This is to avoid cross-dependencies between modules. To pull data handled by multiple modules, you can create a selector outside of the modules that will then use the selectors provided by the individual modules.
We’ve modeled our selectors by the state of the module itself. The selectors themselves have no idea where in the application state the module is mounted. On the initialization step we “globalise” all the selectors. This basically means that we wrap all the module’s selectors with an additional selector that picks the module’s part state from the whole application state and passes it to the “local” scope module selector. This allows us to build and test the selectors with only the shape of the module’s own state in mind. This separation between the module scope state and the store state makes it easier to test all the modules independently.
Wrapping up
This was a introduction to the ways we at Smartly.io look at Redux and Redux modules. Dive deeper into the topic with these goodreads:
- Three Rules For Structuring (Redux) Applications by Jack Hsu
- Ducks: Redux Reducer Bundles by Erik Rasmussen


When we began phasing out Angular in favor of React, we took Redux into use to manage the global application state. In this blog post, I'll explain how we use Redux modules at Smartly.io to create a maintainable codebase.
As a Flux-like implementation, Redux follows a unidirectional data flow architecture, which, in Redux’s terms, means that whenever you need to make a change to an application’s state, you dispatch an action to the store. Reducers in the store then decide if they need to make any changes to their own state, depending on the action. Finally, the new state propagates to the view layer to all the components that are listening to the changes.
This pattern takes all the hassle away from debugging your application state, as only the reducers change your application state and they work exclusively based on the dispatched actions. However, there is more to be done for a clean Redux codebase and that’s where the modules come in!
In and out
When developing React components, it is a commonly encouraged pattern to split the logic and view. With our Redux setup, we aim to split the state logic and view layer completely. Providing clear APIs for interacting with the application state allows us to isolate the inner workings of our state machine from the view layer. In Redux, those APIs are actions for changing state and selectors for reading the state. Let’s talk more about actions and selectors later.
Redux as modules
The module structure for Redux is all about dividing code by domain areas and eliminating dependencies between the modules. When a developer needs to make changes to the massive code-base it is easier to find out which module is responsible for the area requiring the changes, how different actions affect the module state, and what you can actually pull out from the module. One example of a module could be named “Campaigns” with the responsibility of managing lists and details of user’s campaigns within the application state tree.
What do the modules contain?
The “Campaigns” module provides its own reducer, actions, selectors, and optionally some utils, constants etc. The utils in this case are any functional helpers that are related to the domain of the module.
Typical module structure is as follows:
1. Reducer
The module reducer will manage a very specific subset of the whole application state. A “Campaigns” module reducer would only be managing state related to campaigns: list of campaigns, changes to campaign data, loading states for the module data etc. The whole application state is managed by a combined reducer built with all of our individual module reducers.
The application state with the different modules mounted on it might look something like this. The individual keys represent the modules and their own areas of responsibility.
2. Action creators
The module also contains action creators for creating actions that will be handled by its reducer. We decided to name our actions with the pattern <project>/<module>/<ACTION_NAME> so ie. “smartly/campaigns/CREATE_CAMPAIGN”. The pattern is known from Erik Rasmussen’s proposal “Ducks: Redux Reducer Bundles”. The pattern makes it easy to spot the right project, right module, and right action when looking through the list of actions in Redux DevTools. This naming convention also helps avoid clashes in naming. Clashes can cause weird states as Redux doesn’t care where the action came from—it only cares about the “action.type” string when matched with reducer’s action handlers.
3. Selectors
Redux already takes good care of making sure all state changes are caused by dispatching actions to the store. However, when connecting your components to the store, the whole state is usually passed to the component. In some cases, it might be tempting to simply pick data like “state.myLittleModule.items”,ut then you’re actually making your data component aware of the shape of your whole state. What happens when “items” is no longer under “state.myLittleModule”?
The module specific selectors are used to pull data from the part of the application state that represents the module. Each module provides its own selectors for directly reading the module state. We typically use selectors in a Higher-Order Component that maps the selected values as props for our component. The selectors are called with the application state and, optionally, some additional arguments.
The additional arguments can be used ie. in a selector “getCampaignsByAccountId” to provide the selector with the account ID for filtering. Developers should make sure that the module selectors only read those parts of the data that are covered by the module itself. This is to avoid cross-dependencies between modules. To pull data handled by multiple modules, you can create a selector outside of the modules that will then use the selectors provided by the individual modules.
We’ve modeled our selectors by the state of the module itself. The selectors themselves have no idea where in the application state the module is mounted. On the initialization step we “globalise” all the selectors. This basically means that we wrap all the module’s selectors with an additional selector that picks the module’s part state from the whole application state and passes it to the “local” scope module selector. This allows us to build and test the selectors with only the shape of the module’s own state in mind. This separation between the module scope state and the store state makes it easier to test all the modules independently.
Wrapping up
This was a introduction to the ways we at Smartly.io look at Redux and Redux modules. Dive deeper into the topic with these goodreads:
- Three Rules For Structuring (Redux) Applications by Jack Hsu
- Ducks: Redux Reducer Bundles by Erik Rasmussen



Honestly, we'd rather just show you.
Chat with our team to see how Smartly transforms the fragmented advertising ecosystem into something suspiciously manageable.



%201%20(1)%201%201.avif)
