Tutorial: How We Productized Bayesian Revenue Estimation with Stan
Online advertisers are moving to optimize total revenue on ad spend instead of just pumping up the number of conversions or clicks. Maximizing revenue is tricky as there is a huge random variation in the revenue amounts brought in by individual users. If this isn’t taken into account, it's easy to react to the wrong signals and waste money on less successful ad campaigns. Luckily, Bayesian inference allows us to make justified decisions on a granular level by modeling the variation in the observed data.
Probabilistic programming languages, like Stan, make Bayesian inference easy. Stan provides a flexible way to define the models and do inference, and it has great diagnostic tools like ShinyStan. Probabilistic programming languages are the same for Bayesian modeling as TensorFlow or Keras are for deep learning. Deep learning has become widely adopted in recent years thanks to the developed frameworks. The same is happening now with Bayesian modeling.
Currently, Stan is mainly used for making descriptive analyses of static data collection. Running it in production is possible but challenging. In this blog post, we describe our experiences in getting Stan running in production. We also go through the basic modeling for our specific use case: modeling the revenue per purchase to compare the performance between multiple ads. We discuss in detail how this use case can be solved by using Bayesian multilevel modeling in Stan in production.
- Use case: Maximizing the revenue on ad spend
- How to model the revenue?
- Modeling the revenue per purchase
- Multilevel modeling for sharing information
- Analyzing the revenue model
- Experiences in Bayesian modeling with Stan
- Discussion
Use case: Maximizing the revenue on ad spend
Online advertising has traditionally focused on getting impressions and clicks. In recent years, most advertisers have moved towards directly optimizing the conversions on their web page or mobile app. Conversion in advertising can mean anything from online purchases to completing a level in a game. In this case, advertisers want to maximize the number of conversions they get, or in other words, minimize the cost-per-action (CPA) with a given budget.
Today, we see that advertisers aim to maximize the total revenue from conversions instead of just growing the conversion count (and that’s what we discuss in this blog post). In the future, advertisers will be able to maximize the expected lifetime value of a single conversion: the customer may return to buy more in the future, or attract their friends as new customers.

The deeper we go down the funnel, the less data we have to justify our decisions. For example, if 100,000 people see your ad per day, 1% of them click the ad, which results in 1,000 site visits. Out of those site visits, only 1% lead to a purchase. The revenue and lifetime value for those 10 people doing the purchase may vary a lot. Although there is little data with a lot of random variation, you still need to decide where to put your advertising budget tomorrow. Bayesian inference solves this problem by quantifying the uncertainty.
On the revenue side, the most common metric is the return-on-ad-spend (ROAS) which means the total revenue per advertising spend. Interestingly, the ROAS can be separated into two parts:

Thus, to estimate the ROAS for a single ad, you can estimate the CPA and the revenue per conversion levels separately. Similarly, CPA can be further separated into modeling how many impressions per spend, clicks per impressions, and conversions per clicks you get. When comparing the performance between the ads, these parts usually differ a lot in their behavior (check the conversion funnel below).

At Smartly.io, we already had a model in place for the cost-per-action part that utilizes this funnel and is able to react fast to changes. It’s used as part of our budget allocation that’s based on Bayesian multi-armed bandits and allocates the budget between multiple ad sets based on their performance. To change our Predictive Budget Allocation to optimize towards ROAS instead of CPA, we only needed to plug in stable estimates for the mean distributions of the revenue per conversion for multiple ads (or actually ad sets in the Facebook context as budget and target audience is defined on that level).
How to model the revenue?
Modeling the revenue per purchase
Although the revenue per conversion can vary a lot between single purchases, most of that variation is usually normal random variation and not due to differences between the ad sets. For example, if you get ten purchases out of which nine bring $10 in revenue each and the last one brings $1,000, your average revenue per conversion would be close to $100. Without that single big purchase, the average would be $10. If you had to predict the average revenue per conversion for tomorrow, would you say it’s closer to $10 than $100? If your second ad set also had ten purchases but all of them brought revenue close to $20, on which of the ad sets would you bet your money?
In most cases, we’ve seen that ad sets don’t differ in the average revenue per conversion they bring, although the raw numbers would indicate a big difference. For the ad sets to really have a difference in the revenue per conversion they generate, the advertising targeting audiences or offers should really impact the revenue generation process on the advertisers’ end. For example, ad sets targeted to different countries could bring different revenue per conversion.
Ok, how can we then get stable estimates to compare the performance between ad sets? Here the Bayesian multilevel modeling comes to the stage. In multilevel modeling, you can say that the ad sets are similar to each other unless data proves otherwise. Let’s start by estimating the revenue per conversion for a single ad set first.

Revenue usually follows a heavy-tailed distribution. That means that most of the revenue amounts are small but there can be some conversions with very large revenue amounts. Above, is a real example of the distribution of revenues for all purchases in an e-commerce advertising account. We model the revenue per conversion by using a log-normal distribution. Below, is the same distribution with logarithmic transformation. It’s fairly close to a normal distribution, supporting the feasibility of the log-normal approach.

Thus, we assume that the revenue of single conversion Ra for an ad set follows a log-normal distribution with location and scale parameters 𝜃a and 𝜎a that can vary between ad sets.

We don’t get data about every single conversion from Facebook, which complicates things a bit. Instead, we get daily or hourly aggregates of the total revenue and conversions for the ad sets. We can approximate these observational level revenues Ri with another log-normal distribution whose mean and variance are matched with the mean and variance of the sum of ni independent and identically distributed log-normal random variables (Fenton-Wilkinson approximation). Let ai be the ad set of the observation i. Then

It’s interesting to note that the mean of log-normally distributed random variable Ra is not directly the same as the mode and median exp(𝜃a) of the distribution but instead

That’s why the rare but large revenue amounts should be included when estimating revenue means.
To simplify the model, we assume that the revenue per conversion Ra doesn’t change over time. The time-series variation is taken into account in the CPA modeling. So, we pool all the hourly revenue data from the previous two weeks together for a single ad set. We use hourly data to get as close to transactional data as possible.
Given now the observed revenues ri and counts ni we could estimate the log-normal parameters 𝜃a and 𝜎a directly by writing a model in Stan. We aren’t interested in getting a point estimate for these (maximum a posteriori, MAP), but instead in getting samples from the posterior distribution to capture also the uncertainty in the estimation.
For a complete model, we’d need some reasonable priors for the location and scale parameters. If the priors are excluded, Stan automatically uses uninformative priors. Below, is a simple Stan code implementing the non-hierarchical estimation for modeling the revenues.
What’s nice about Stan is that our model definition turns almost line-by-line into the final code. However, getting this model to fit by Stan is hard, as we haven’t specified any limits for the variables, or given sensible priors. The model fails to fit. We’ll return to this later.
Multilevel modeling for sharing information
The issue with the first approach is that the ad set estimates would be based on just the data from the individual ad sets. In this case, one random large $1,000 purchase can affect the mean estimate of a single ad set radically if there are only tens of conversion events (which is a common case). As such large revenue events could have happened also in other ad sets, we can get better estimates by sharing information between the ad sets.
With multilevel modeling, we can implement a partial pooling approach to share information. The first model above corresponds to the no-pooling approach. Full pooling would mean combining the data from all ad sets together and producing a single shared estimate for all of them. If there is little data, the multilevel model produces similar results to full pooling. If there is a lot of data, it produces results close to no-pooling.
As log-normally distributed revenue events are quite volatile, a lot of data is needed for stable estimates, which makes partial pooling appealing. With partial pooling, the estimates are attracted towards the shared mean, if the ad set doesn’t have enough data to estimate its own parameters.

Examples of different levels of pooling with two ad sets.
In our model, we use the simple Facebook advertising hierarchy: advertising account > campaign > ad set. That is, ad sets inside one campaign are expected to be more similar than ad sets in other campaigns in the account. To specify this hierarchy, let ca be the campaign where the ad set belongs. We assume that the ad set level parameters 𝜃a and 𝜎a have a shared campaign level prior. Let’s focus first on the location parameters 𝜃a which we model in three steps:
- Campaign level Normal prior for 𝜃a with parameters 𝜇c and 𝜏
- Account-level prior for the campaign level location parameter 𝜇c
- Improper uniform prior on a logarithmic scale for the account level scale 𝜆
Then the multilevel model for the location parts looks like

Thus, ad set level means 𝜃a are expected to be close to campaign level mean 𝜇c if the campaign level scales 𝜏c are small. This gives partial pooling.
Next, we should assign priors for the scale parameters 𝜎a. Here we simplify the model further by assuming that all the log-normal scale parameters are shared between the ad sets on the account level. This simplification corresponds to setting a strong prior. Note that as the final model is a log-normal, these scale parameters turn to relative differences instead of absolute ones. As we are interested mainly in the difference in the means of the distributions, this assumption works as a good starting point and fixes the main issue with possible random big revenue observations.
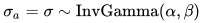
We model the main scale parameter 𝜎 of the log-normal revenue distribution to follow an inverse gamma distribution with parameters 𝛼 and 𝛽. We set informative prior by using parameter values 𝛼 = 6 and 𝛽 = 4 based on real data, making the mean of 𝜎 to be around 2/3 a priori but allowing it to easily vary if there’s enough data present.
For a complete model, we are missing only hyper-priors for the scale parameters 𝜏c and 𝜙 in the multilevel model. To simplify again, we assume that campaigns share the scale parameter 𝜏c. We give for both of them a separate weak exponential prior that has a peak in zero and mean 1/𝛾 around 0.05.

So in the end, there are quite many steps in defining a multilevel model although we made quite many simplifications on the way to get started. To improve the model, we could also model the scale parameters with hierarchy by using for example additive Cauchy priors as explained in Tauman, Chapter 6. Modeling the time-series effect would be beneficial, for example, by using Bayesian structural time-series models. Also, instead of using normal multilevel priors, t-distribution is used quite commonly to allow more variation.
However, it’s better to start from a simple model since our goal is to get something that we can run automatically for different types of data in a scalable way. Improvements should be done only based on validating the performance with real data. The updated Stan models with the new hierarchy are shown below. Also, strict limits have been added for the parameters based on the analysis over hundreds of accounts. In addition, we have used standard reparametrization to speed up the model, see Stan-manual, 26.6, Hierarchical Models, and the Non-Centered Parameterization, for more details.
Analyzing the revenue model
Finally, we have a model that we can fit with Stan and analyze the results. We get the revenue distribution estimates for each ad set. From this output, we’re especially interested in the mean distributions.
It’s always good to start by checking how well our model describes the data by generating new data based on the fitted model and compare that to the original data. This is called posterior predictive check. Below are the posterior predictive check results for the original ad set revenue observations (green) with data generated from the model (blue) on a log scale. The model seems to fit nicely with the data. The original data contains one bigger peak. There can be for example one single product price explaining this but it’s nothing worrying.

We can now compare the individual ad set revenue mean distributions, as well as the campaign level distributions as shown below. Ad sets in the same campaign share the color. In this case, we see that distributions overlap a lot and that the ad sets inside a single campaign don’t differ. There are a lot of ad sets but little data per ad set. The campaigns differ slightly from each other.

One interesting aspect is to compare the raw average calculated directly from the observations to the average calculated from the model. The plot below does it for all of the ad sets with 95% prediction intervals. The raw averages vary between 4.6 and 5.2 on a log scale, meaning about 4x bigger observed revenue per conversion between the smallest and largest ad set. In the fitted model, we get only about 25% larger estimates at max. This is due to the partial pooling effect, which is represented in the plot by almost all dots being on a horizontal line.

We have run similar plots for all of our accounts on production to check that the model works reasonably. Although there are a lot of plots to check manually, it’s still the easiest and fastest way to identify issues in the model. The posterior predictive data should match with the original data. The partial pooling should flatten the results if there is little data present or if there really aren’t any differences.
In most cases, we observed that the ad sets are heavily pooled together. However, there are cases where the ad sets indeed differ from each other and no pooling happens. Also, sometimes the campaign hierarchy doesn’t bring additional value, unlike in the plots above.
Experiences in Bayesian modeling with Stan
All the Bayesian multilevel modeling details with different distributions and parameters may look complicated—and they are. Stan doesn’t make it easier. It’s good to read something like Doing Bayesian Data Analysis by John K. Kruschke or Bayesian Data Analysis by Gelman et al to understand more about Bayesian data analysis.
However, after you get comfortable in writing models, Stan is an expressive language that takes away the need to write custom optimization or sampling code to fit your model. It allows you to modify the model and add complexity easily. For the CPA modeling side, we’re still using a custom-built model in Python by relying on conjugate distributions and approximations. It works well but changing it is somewhat cumbersome. In the future, we could use Stan also for that part.
The model fitting in Stan is based on sampling and Markov chains. Roughly, the process starts from random initial values for the parameters and at each step, they are slightly modified. If the new parameter values produce a better fit for the data, they are accepted. If worse, they are accepted with a probability defined by the Metropolis-Hastings Markov chain Monte Carlo (MCMC) method. After a warmup time, we get samples from the posterior distribution.
Simple MCMC can be very slow. Stan uses advanced techniques like no-u-turn-sampling (NUTS) with Hamiltonian Monte Carlo (HMC) to speed up the sampling. With larger datasets, this is often still too slow. There are various other approximative methods that alleviate the issue. For example, you can just calculate the maximum-a-posteriori (MAP) point estimate which is very fast but doesn’t usually work well with multilevel models and is not able to catch the uncertainties.
Variational Bayesian inference is another approximative method where the posterior distribution is approximated by a variational distribution, usually a normal distribution. This works well if the model is fairly simple, as it is in our case. Stan implements an automatic differentiation variational inference (ADVI) that was released at the end of 2016.
Current ADVI implementation is still in early-stage and it’s good to make sure that it produces similar results to full sampling before using it in production. ADVI came available for the PyStan Python interface in April 2017, and now we’re using it in production. We had evaluated Stan and other probabilistic programming languages a few times earlier but they never scaled to our use cases. ADVI enabled us to use Stan in production.
However, using Stan was still painful. The model fitting can easily crash if the learning diverges. In most cases that can be fixed by adding sensible limits and informative priors for the variables and possibly adding a custom initialization for the parameters. Also, non-centered parameterization is needed for hierarchical models.
These are must-haves for running the model in production. You want the model to fit 100% of the cases and not just 90% which would be fine in interactive mode. However, finding the issues with the model is hard. The best is to start with a really simple model and add stuff step-by-step. Also running the model against various data sets and producing posterior plots automatically helps in identifying the issues early. For optimization of the Stan code further, refer to section 26, Optimization Stan Code for Efficiency.
Stan code needs compilation and that can be slow. It can be avoided by caching the models. But when you’re developing and debugging the model, it can be really frustrating. Nevertheless, it’s still compiled C++ code that gets wrapped via PyStan interface. The interface would need some more love. It’s far from RStan which is the most commonly used interface. But we use Python as it’s nicer for productized analytics.
For scheduling, we use Celery which is a nice distributed task queue. We validated also Azkaban, Airflow, and other common analytics scheduling systems but found out that the standard Python scheduler is just easier to use.
Discussion
Bayesian modeling is becoming mainstream in many application areas. Applying it needs still a lot of knowledge about distributions and modeling techniques but the recent development in probabilistic programming languages has made it much more tractable. Stan is a promising language that suits single analysis cases well. With the improvements in approximation methods, it can scale to production level if care is taken in defining and validating the model. The model described here is the basis for the model we are running in production with various additional improvements.
We had plans to compare Stan also to other probabilistic programming languages, namely PyMC3 and Edward, but getting just Stan working in our case was challenging enough. We hope to do such a comparison in the future. Luckily Bob Carpenter has done an excellent comparison blog post about the same topic. Briefly, PyMC3 seems to provide the smoothest integration with Python but lacking in modeling features. Edward is on the other hand very low-level language built on top of TensorFlow supporting also state-of-the-art variational inference methods. It’s a very bleeding edge with a lot of breaking changes, making it a bit risky choice for production use.
We are now running the revenue model for thousands of different accounts every night with varying amounts of campaigns, ad sets, and revenue observations. The longest run takes couple minutes. Most of our customers still use conversion optimization but are transitioning to use the revenue optimization feature. Overall, about one million euros of advertising spend on daily level is managed with our Predictive Budget Allocation. In future, we see that Stan or some other probabilistic programming language plays a big role in the optimization features of Smartly.io.
Would you like to work with us?
Check out our open engineering positions and apply! https://boards.greenhouse.io/smartlyio
Tutorial: How We Productized Bayesian Revenue Estimation with Stan



Online advertisers are moving to optimize total revenue on ad spend instead of just pumping up the number of conversions or clicks. Maximizing revenue is tricky as there is a huge random variation in the revenue amounts brought in by individual users. If this isn’t taken into account, it's easy to react to the wrong signals and waste money on less successful ad campaigns. Luckily, Bayesian inference allows us to make justified decisions on a granular level by modeling the variation in the observed data.
Probabilistic programming languages, like Stan, make Bayesian inference easy. Stan provides a flexible way to define the models and do inference, and it has great diagnostic tools like ShinyStan. Probabilistic programming languages are the same for Bayesian modeling as TensorFlow or Keras are for deep learning. Deep learning has become widely adopted in recent years thanks to the developed frameworks. The same is happening now with Bayesian modeling.
Currently, Stan is mainly used for making descriptive analyses of static data collection. Running it in production is possible but challenging. In this blog post, we describe our experiences in getting Stan running in production. We also go through the basic modeling for our specific use case: modeling the revenue per purchase to compare the performance between multiple ads. We discuss in detail how this use case can be solved by using Bayesian multilevel modeling in Stan in production.
- Use case: Maximizing the revenue on ad spend
- How to model the revenue?
- Modeling the revenue per purchase
- Multilevel modeling for sharing information
- Analyzing the revenue model
- Experiences in Bayesian modeling with Stan
- Discussion
Use case: Maximizing the revenue on ad spend
Online advertising has traditionally focused on getting impressions and clicks. In recent years, most advertisers have moved towards directly optimizing the conversions on their web page or mobile app. Conversion in advertising can mean anything from online purchases to completing a level in a game. In this case, advertisers want to maximize the number of conversions they get, or in other words, minimize the cost-per-action (CPA) with a given budget.
Today, we see that advertisers aim to maximize the total revenue from conversions instead of just growing the conversion count (and that’s what we discuss in this blog post). In the future, advertisers will be able to maximize the expected lifetime value of a single conversion: the customer may return to buy more in the future, or attract their friends as new customers.
The deeper we go down the funnel, the less data we have to justify our decisions. For example, if 100,000 people see your ad per day, 1% of them click the ad, which results in 1,000 site visits. Out of those site visits, only 1% lead to a purchase. The revenue and lifetime value for those 10 people doing the purchase may vary a lot. Although there is little data with a lot of random variation, you still need to decide where to put your advertising budget tomorrow. Bayesian inference solves this problem by quantifying the uncertainty.
On the revenue side, the most common metric is the return-on-ad-spend (ROAS) which means the total revenue per advertising spend. Interestingly, the ROAS can be separated into two parts:
Thus, to estimate the ROAS for a single ad, you can estimate the CPA and the revenue per conversion levels separately. Similarly, CPA can be further separated into modeling how many impressions per spend, clicks per impressions, and conversions per clicks you get. When comparing the performance between the ads, these parts usually differ a lot in their behavior (check the conversion funnel below).
At Smartly.io, we already had a model in place for the cost-per-action part that utilizes this funnel and is able to react fast to changes. It’s used as part of our budget allocation that’s based on Bayesian multi-armed bandits and allocates the budget between multiple ad sets based on their performance. To change our Predictive Budget Allocation to optimize towards ROAS instead of CPA, we only needed to plug in stable estimates for the mean distributions of the revenue per conversion for multiple ads (or actually ad sets in the Facebook context as budget and target audience is defined on that level).
How to model the revenue?
Modeling the revenue per purchase
Although the revenue per conversion can vary a lot between single purchases, most of that variation is usually normal random variation and not due to differences between the ad sets. For example, if you get ten purchases out of which nine bring $10 in revenue each and the last one brings $1,000, your average revenue per conversion would be close to $100. Without that single big purchase, the average would be $10. If you had to predict the average revenue per conversion for tomorrow, would you say it’s closer to $10 than $100? If your second ad set also had ten purchases but all of them brought revenue close to $20, on which of the ad sets would you bet your money?
In most cases, we’ve seen that ad sets don’t differ in the average revenue per conversion they bring, although the raw numbers would indicate a big difference. For the ad sets to really have a difference in the revenue per conversion they generate, the advertising targeting audiences or offers should really impact the revenue generation process on the advertisers’ end. For example, ad sets targeted to different countries could bring different revenue per conversion.
Ok, how can we then get stable estimates to compare the performance between ad sets? Here the Bayesian multilevel modeling comes to the stage. In multilevel modeling, you can say that the ad sets are similar to each other unless data proves otherwise. Let’s start by estimating the revenue per conversion for a single ad set first.
Revenue usually follows a heavy-tailed distribution. That means that most of the revenue amounts are small but there can be some conversions with very large revenue amounts. Above, is a real example of the distribution of revenues for all purchases in an e-commerce advertising account. We model the revenue per conversion by using a log-normal distribution. Below, is the same distribution with logarithmic transformation. It’s fairly close to a normal distribution, supporting the feasibility of the log-normal approach.
Thus, we assume that the revenue of single conversion Ra for an ad set follows a log-normal distribution with location and scale parameters 𝜃a and 𝜎a that can vary between ad sets.
We don’t get data about every single conversion from Facebook, which complicates things a bit. Instead, we get daily or hourly aggregates of the total revenue and conversions for the ad sets. We can approximate these observational level revenues Ri with another log-normal distribution whose mean and variance are matched with the mean and variance of the sum of ni independent and identically distributed log-normal random variables (Fenton-Wilkinson approximation). Let ai be the ad set of the observation i. Then
It’s interesting to note that the mean of log-normally distributed random variable Ra is not directly the same as the mode and median exp(𝜃a) of the distribution but instead
That’s why the rare but large revenue amounts should be included when estimating revenue means.
To simplify the model, we assume that the revenue per conversion Ra doesn’t change over time. The time-series variation is taken into account in the CPA modeling. So, we pool all the hourly revenue data from the previous two weeks together for a single ad set. We use hourly data to get as close to transactional data as possible.
Given now the observed revenues ri and counts ni we could estimate the log-normal parameters 𝜃a and 𝜎a directly by writing a model in Stan. We aren’t interested in getting a point estimate for these (maximum a posteriori, MAP), but instead in getting samples from the posterior distribution to capture also the uncertainty in the estimation.
For a complete model, we’d need some reasonable priors for the location and scale parameters. If the priors are excluded, Stan automatically uses uninformative priors. Below, is a simple Stan code implementing the non-hierarchical estimation for modeling the revenues.
What’s nice about Stan is that our model definition turns almost line-by-line into the final code. However, getting this model to fit by Stan is hard, as we haven’t specified any limits for the variables, or given sensible priors. The model fails to fit. We’ll return to this later.
Multilevel modeling for sharing information
The issue with the first approach is that the ad set estimates would be based on just the data from the individual ad sets. In this case, one random large $1,000 purchase can affect the mean estimate of a single ad set radically if there are only tens of conversion events (which is a common case). As such large revenue events could have happened also in other ad sets, we can get better estimates by sharing information between the ad sets.
With multilevel modeling, we can implement a partial pooling approach to share information. The first model above corresponds to the no-pooling approach. Full pooling would mean combining the data from all ad sets together and producing a single shared estimate for all of them. If there is little data, the multilevel model produces similar results to full pooling. If there is a lot of data, it produces results close to no-pooling.
As log-normally distributed revenue events are quite volatile, a lot of data is needed for stable estimates, which makes partial pooling appealing. With partial pooling, the estimates are attracted towards the shared mean, if the ad set doesn’t have enough data to estimate its own parameters.
Examples of different levels of pooling with two ad sets.
In our model, we use the simple Facebook advertising hierarchy: advertising account > campaign > ad set. That is, ad sets inside one campaign are expected to be more similar than ad sets in other campaigns in the account. To specify this hierarchy, let ca be the campaign where the ad set belongs. We assume that the ad set level parameters 𝜃a and 𝜎a have a shared campaign level prior. Let’s focus first on the location parameters 𝜃a which we model in three steps:
- Campaign level Normal prior for 𝜃a with parameters 𝜇c and 𝜏
- Account-level prior for the campaign level location parameter 𝜇c
- Improper uniform prior on a logarithmic scale for the account level scale 𝜆
Then the multilevel model for the location parts looks like
Thus, ad set level means 𝜃a are expected to be close to campaign level mean 𝜇c if the campaign level scales 𝜏c are small. This gives partial pooling.
Next, we should assign priors for the scale parameters 𝜎a. Here we simplify the model further by assuming that all the log-normal scale parameters are shared between the ad sets on the account level. This simplification corresponds to setting a strong prior. Note that as the final model is a log-normal, these scale parameters turn to relative differences instead of absolute ones. As we are interested mainly in the difference in the means of the distributions, this assumption works as a good starting point and fixes the main issue with possible random big revenue observations.
We model the main scale parameter 𝜎 of the log-normal revenue distribution to follow an inverse gamma distribution with parameters 𝛼 and 𝛽. We set informative prior by using parameter values 𝛼 = 6 and 𝛽 = 4 based on real data, making the mean of 𝜎 to be around 2/3 a priori but allowing it to easily vary if there’s enough data present.
For a complete model, we are missing only hyper-priors for the scale parameters 𝜏c and 𝜙 in the multilevel model. To simplify again, we assume that campaigns share the scale parameter 𝜏c. We give for both of them a separate weak exponential prior that has a peak in zero and mean 1/𝛾 around 0.05.
So in the end, there are quite many steps in defining a multilevel model although we made quite many simplifications on the way to get started. To improve the model, we could also model the scale parameters with hierarchy by using for example additive Cauchy priors as explained in Tauman, Chapter 6. Modeling the time-series effect would be beneficial, for example, by using Bayesian structural time-series models. Also, instead of using normal multilevel priors, t-distribution is used quite commonly to allow more variation.
However, it’s better to start from a simple model since our goal is to get something that we can run automatically for different types of data in a scalable way. Improvements should be done only based on validating the performance with real data. The updated Stan models with the new hierarchy are shown below. Also, strict limits have been added for the parameters based on the analysis over hundreds of accounts. In addition, we have used standard reparametrization to speed up the model, see Stan-manual, 26.6, Hierarchical Models, and the Non-Centered Parameterization, for more details.
Analyzing the revenue model
Finally, we have a model that we can fit with Stan and analyze the results. We get the revenue distribution estimates for each ad set. From this output, we’re especially interested in the mean distributions.
It’s always good to start by checking how well our model describes the data by generating new data based on the fitted model and compare that to the original data. This is called posterior predictive check. Below are the posterior predictive check results for the original ad set revenue observations (green) with data generated from the model (blue) on a log scale. The model seems to fit nicely with the data. The original data contains one bigger peak. There can be for example one single product price explaining this but it’s nothing worrying.
We can now compare the individual ad set revenue mean distributions, as well as the campaign level distributions as shown below. Ad sets in the same campaign share the color. In this case, we see that distributions overlap a lot and that the ad sets inside a single campaign don’t differ. There are a lot of ad sets but little data per ad set. The campaigns differ slightly from each other.
One interesting aspect is to compare the raw average calculated directly from the observations to the average calculated from the model. The plot below does it for all of the ad sets with 95% prediction intervals. The raw averages vary between 4.6 and 5.2 on a log scale, meaning about 4x bigger observed revenue per conversion between the smallest and largest ad set. In the fitted model, we get only about 25% larger estimates at max. This is due to the partial pooling effect, which is represented in the plot by almost all dots being on a horizontal line.
We have run similar plots for all of our accounts on production to check that the model works reasonably. Although there are a lot of plots to check manually, it’s still the easiest and fastest way to identify issues in the model. The posterior predictive data should match with the original data. The partial pooling should flatten the results if there is little data present or if there really aren’t any differences.
In most cases, we observed that the ad sets are heavily pooled together. However, there are cases where the ad sets indeed differ from each other and no pooling happens. Also, sometimes the campaign hierarchy doesn’t bring additional value, unlike in the plots above.
Experiences in Bayesian modeling with Stan
All the Bayesian multilevel modeling details with different distributions and parameters may look complicated—and they are. Stan doesn’t make it easier. It’s good to read something like Doing Bayesian Data Analysis by John K. Kruschke or Bayesian Data Analysis by Gelman et al to understand more about Bayesian data analysis.
However, after you get comfortable in writing models, Stan is an expressive language that takes away the need to write custom optimization or sampling code to fit your model. It allows you to modify the model and add complexity easily. For the CPA modeling side, we’re still using a custom-built model in Python by relying on conjugate distributions and approximations. It works well but changing it is somewhat cumbersome. In the future, we could use Stan also for that part.
The model fitting in Stan is based on sampling and Markov chains. Roughly, the process starts from random initial values for the parameters and at each step, they are slightly modified. If the new parameter values produce a better fit for the data, they are accepted. If worse, they are accepted with a probability defined by the Metropolis-Hastings Markov chain Monte Carlo (MCMC) method. After a warmup time, we get samples from the posterior distribution.
Simple MCMC can be very slow. Stan uses advanced techniques like no-u-turn-sampling (NUTS) with Hamiltonian Monte Carlo (HMC) to speed up the sampling. With larger datasets, this is often still too slow. There are various other approximative methods that alleviate the issue. For example, you can just calculate the maximum-a-posteriori (MAP) point estimate which is very fast but doesn’t usually work well with multilevel models and is not able to catch the uncertainties.
Variational Bayesian inference is another approximative method where the posterior distribution is approximated by a variational distribution, usually a normal distribution. This works well if the model is fairly simple, as it is in our case. Stan implements an automatic differentiation variational inference (ADVI) that was released at the end of 2016.
Current ADVI implementation is still in early-stage and it’s good to make sure that it produces similar results to full sampling before using it in production. ADVI came available for the PyStan Python interface in April 2017, and now we’re using it in production. We had evaluated Stan and other probabilistic programming languages a few times earlier but they never scaled to our use cases. ADVI enabled us to use Stan in production.
However, using Stan was still painful. The model fitting can easily crash if the learning diverges. In most cases that can be fixed by adding sensible limits and informative priors for the variables and possibly adding a custom initialization for the parameters. Also, non-centered parameterization is needed for hierarchical models.
These are must-haves for running the model in production. You want the model to fit 100% of the cases and not just 90% which would be fine in interactive mode. However, finding the issues with the model is hard. The best is to start with a really simple model and add stuff step-by-step. Also running the model against various data sets and producing posterior plots automatically helps in identifying the issues early. For optimization of the Stan code further, refer to section 26, Optimization Stan Code for Efficiency.
Stan code needs compilation and that can be slow. It can be avoided by caching the models. But when you’re developing and debugging the model, it can be really frustrating. Nevertheless, it’s still compiled C++ code that gets wrapped via PyStan interface. The interface would need some more love. It’s far from RStan which is the most commonly used interface. But we use Python as it’s nicer for productized analytics.
For scheduling, we use Celery which is a nice distributed task queue. We validated also Azkaban, Airflow, and other common analytics scheduling systems but found out that the standard Python scheduler is just easier to use.
Discussion
Bayesian modeling is becoming mainstream in many application areas. Applying it needs still a lot of knowledge about distributions and modeling techniques but the recent development in probabilistic programming languages has made it much more tractable. Stan is a promising language that suits single analysis cases well. With the improvements in approximation methods, it can scale to production level if care is taken in defining and validating the model. The model described here is the basis for the model we are running in production with various additional improvements.
We had plans to compare Stan also to other probabilistic programming languages, namely PyMC3 and Edward, but getting just Stan working in our case was challenging enough. We hope to do such a comparison in the future. Luckily Bob Carpenter has done an excellent comparison blog post about the same topic. Briefly, PyMC3 seems to provide the smoothest integration with Python but lacking in modeling features. Edward is on the other hand very low-level language built on top of TensorFlow supporting also state-of-the-art variational inference methods. It’s a very bleeding edge with a lot of breaking changes, making it a bit risky choice for production use.
We are now running the revenue model for thousands of different accounts every night with varying amounts of campaigns, ad sets, and revenue observations. The longest run takes couple minutes. Most of our customers still use conversion optimization but are transitioning to use the revenue optimization feature. Overall, about one million euros of advertising spend on daily level is managed with our Predictive Budget Allocation. In future, we see that Stan or some other probabilistic programming language plays a big role in the optimization features of Smartly.io.
Would you like to work with us?
Check out our open engineering positions and apply! https://boards.greenhouse.io/smartlyio



Honestly, we'd rather just show you.
Chat with our team to see how Smartly transforms the fragmented advertising ecosystem into something suspiciously manageable.



%201%20(1)%201%201.avif)
